Опис модуля "Розпізнавання тексту (Tesseract OCR)"
Даний модуль призначено для підключення можливостей розпізнавання тексту під час сканування з карточки документу, постачається тільки з комерційними версіями СЕД. Для його роботи до складу системи FossDoc використовується стороннє програмне забезпечення Tesseract, яке поширюється його розробниками вільно за відкритою ліцензією. Для використання даного модулю потрібно, щоб його було включено до серверної ліцензії FossDoc.
Далі буде розглянуто:
Розпізнавання тексту
Команди для розпізнавання тексту знаходяться у меню кнопки Сканування картки документу. Для розпізнавання можна спочатку відсканувати деякий документ (або прикласти вже відсканований документ на закладку файли):
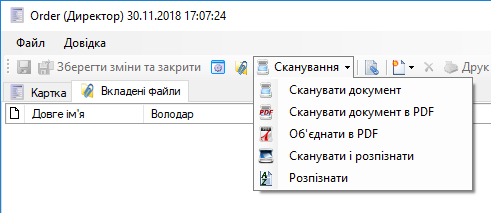
Припустимо ви отримали тим або іншим чином деякі відскановані документи. Натисніть Сканування/Розпізнати, та оберіть файли, для яких необхідно розпізнати текст:
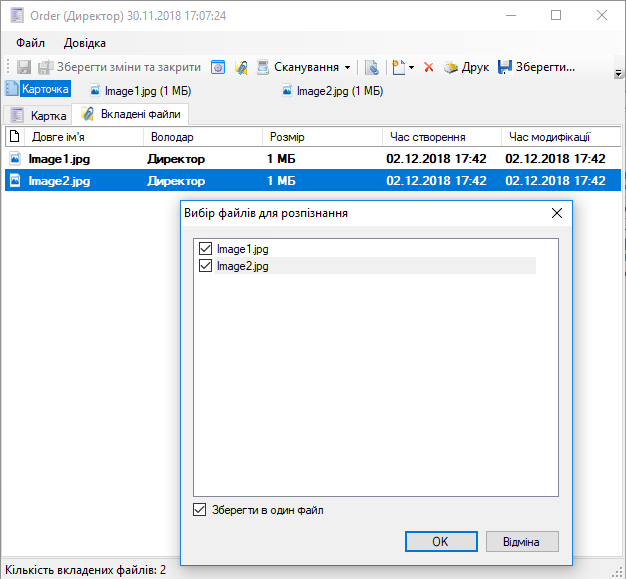
Якщо ви встановите галочку "Зберегти в один файл", система об'єднає тексти з обраних файлів в один файл. У результаті буде створено файл у двох форматах - PDF та TXT. Зазвичай назва файлів - "Document":
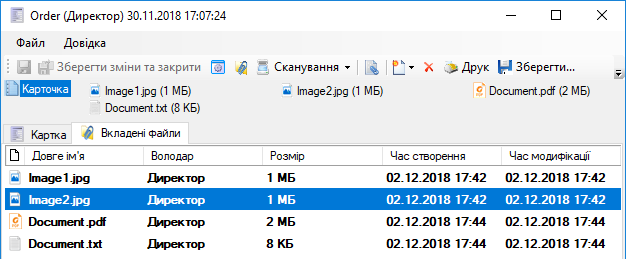
Аналогічним чином ви можете обрати пункт Сканувати та розпізнати, щоб відразу виконати сканування і розпізнавання відсканованого тексту. Після сканування з’явиться діалог:
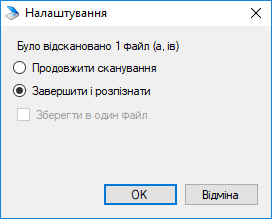
Оберіть пункт Завершити та розпізнати та натисніть ОК. Документ з розпізнаним текстом буде створено. Встановіть галочку Зберегти в один файл для об'єднання декількох документів в один.
Додаткові налаштування модулю
Систему зазвичай налаштовано на розпізнавання тексту на 3 мовах: українська, англійська та російська. Якщо ви впевнені, що для вашої роботи потрібна тільки одна мова для розпізнавання, ви можете обрати в налаштуваннях тільки її, - це дещо скоротить час роботи програми розпізнавання. Для того, щоб обрати одну мову, перейдіть в програмі адміністрування до Бібліотеки документів/Сервер, на закладку Бібліотека серверу, натисніть "Налаштування":
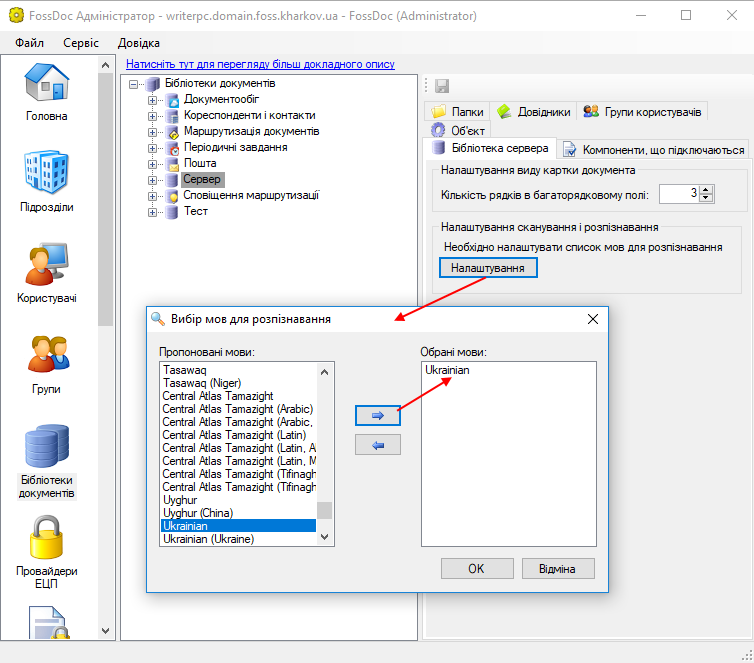
Оберіть необхідну мову, та натисніть ОК.